Blog
Tab Management Is a Prediction Problem
By Maya Sagalin
June 1, 2026
Rich Sutton's bitter lesson is that systems built around hand-coded assumptions tend to lose, over time, to systems that can use data, search, and learning as the problem scales. Tab management has not absorbed this lesson yet. The conventional advice for a user with a hundred Chrome tabs is to close some, bookmark a few, and let a fixed rule sleep the rest after a timer expires. That framing treats the tab bar as a cleanup queue rather than as a live working set whose value changes with the user, the task, and the moment.
Once you look at the tab bar as a working set, the central question changes. The browser should not ask only how long a page has been idle; it should estimate whether that page is likely to be needed soon. A predictor does not have to be magical to be useful. It only has to outperform a global rule that treats a Figma board, a forgotten article, and a half-finished form as equivalent.
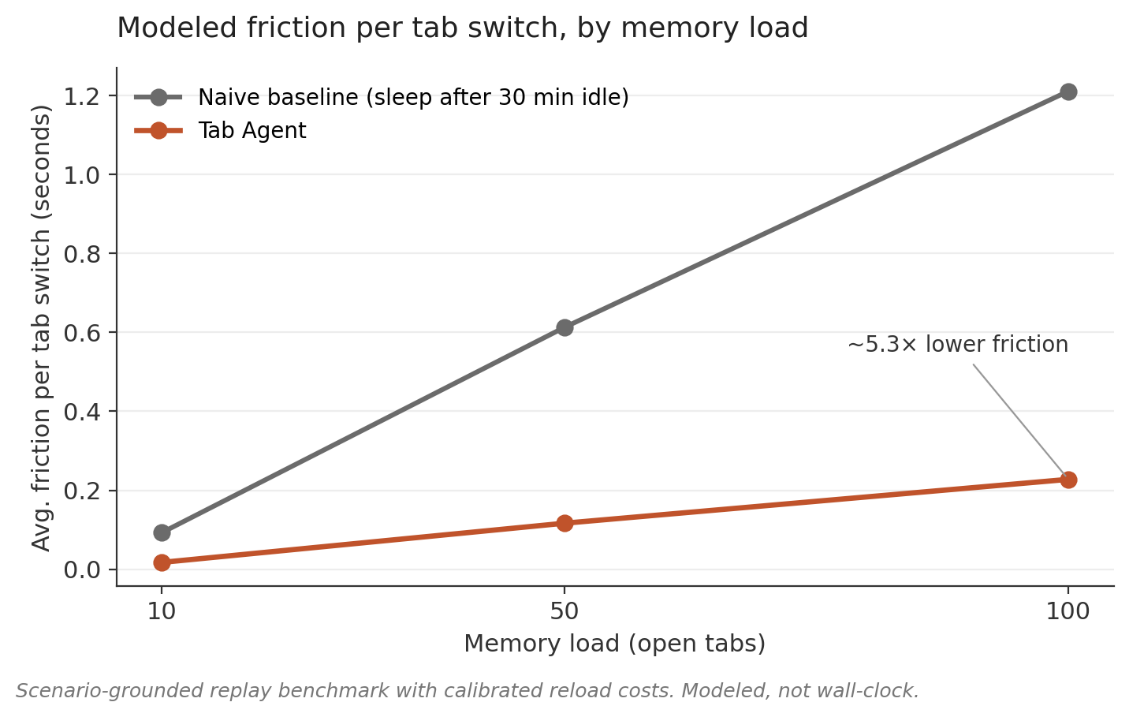
I built Tab Agent to test the alternative. It's a Chrome extension that runs a small local loop on-device using Gemini Nano: observe the tab state, predict near-term need, sleep low-need tabs, wake related ones when context shifts, update from feedback. Against a fixed-rule baseline (the strategy every existing tab-suspender uses), it produces about 5x less modeled friction across loads from 10 to 100 open tabs. Chrome still pays the same cost when a discarded page has to be restored. The difference is upstream: Tab Agent makes fewer sleep decisions that later become cold reactivations.
What follows is why the cleanup framing is wrong, what the right framing looks like, what I built, and what the benchmark proves and what it doesn't.
The cleanup framing and why it fails
If you've ever closed a tab and reopened the same page within an hour, you've personally generated evidence against the cleanup framing. You didn't have too many tabs. You had the wrong tabs closed.
Every dominant tab-suspending tool (Chrome's own Memory Saver, The Marvellous Suspender, Tab Wrangler) sleeps tabs based on time alone. Inactive for thirty minutes? Sleep it. The Figma tab you check every twenty minutes during a design review gets the same treatment as the news article you opened in October and forgot about. When you swipe back to Figma, Chrome has to discard the page from memory and reload it: network requests, JS execution, a re-render. For heavy SaaS pages this is expensive. Hundreds of milliseconds, sometimes a few seconds, plus the cognitive cost of context being momentarily gone when you expected it to be there.
Call that a friction event. The moment when "I need this tab" runs into a noticeable delay before "I'm back in flow." Cleanup-mode tools generate a lot of these, because the rule that decides whether to sleep a tab (elapsed idle time) has almost nothing to do with the rule that determines whether the tab will be needed soon (the user's actual return pattern).
Concretely: in my replay benchmark, a fixed 30-minute-idle policy at 100 open tabs produced a friction event on 75.66% of tab switches. Three out of every four times the user moved between tabs, they hit a cold reactivation. At 50 tabs, still 64.5%. The cleanup strategy doesn't just fail to help at scale, it actively makes the experience worse, because it confidently sleeps tabs the user is about to return to.
The problem isn't that thirty minutes is the wrong threshold. It's that no fixed threshold can work, because the right answer depends on which tab it is and which user is sitting in front of it. A static rule is a guess that ignores every signal that would make the guess better.
What you actually want is a predictor
Look at the problem from the user's side. They have N tabs open. At any moment, only a small subset is live, being used or about to be. The rest are dormant in some loose sense, but not all dormant tabs are equal. Some are reference material the user will swipe back to in five minutes. Some are an article they're done with. Some are a tool they use twenty times a day at predictable rhythms. Some are a half-finished form they care about more than anything else in the window.
The browser has access to a surprising amount of signal that distinguishes these. How often the tab is activated. The typical interval between activations. Whether the user has explicitly protected it. Whether other tabs in its context are currently active. Whether the user has previously rage-undone an attempt to close it. None of this signal is used by fixed-rule tab management. All of it would matter to a predictor.
So the right question isn't "have thirty minutes passed." It's: for each tab, what's the probability it'll be needed in the next fifteen minutes, given what we've seen about this user, this session, and this tab? Sleep the tabs whose predicted need is low. Wake the ones whose predicted need just spiked. Stay out of the user's way otherwise.
This is a small prediction problem. It doesn't require a frontier model, a cloud roundtrip, or a vector database. It needs a controller that observes browser state, makes a probabilistic call, takes a conservative action, and updates its policy from outcomes. That's an agent in the most modest sense: a closed-loop controller, not an autonomous decision-maker. The autonomy boundary is narrow on purpose, and I'll come back to it.
Tab Agent: the loop
Tab Agent is a local-first Chrome extension. The controller runs entirely on-device using Gemini Nano, the small model Chrome ships with via the Prompt API. No API key, no account, nothing leaves the machine. There's an optional cloud layer for evaluation telemetry during user studies, but it's separable from the controller and the product works without it.
The loop is four steps: observe, predict, act, learn.
Observe is the boring, important part. A background service worker logs tab lifecycle events (creates, activations, switches, discards, closes) along with the active tab, cached group assignments, asleep state, recent activations, and any tabs the user has explicitly marked as protected. Visit history is stored in chrome.storage.local. URLs are the stable identifier; I deliberately do not key on Chrome tab IDs because they go stale after a discard, which is a footgun every naive tab manager eventually trips on.
Predict runs against the observed state. The job is narrow: estimate near-term need per tab. The current implementation is a heuristic policy. Recency, activation frequency, context co-occurrence, protected-context membership, and a few derived signals combine into a need score. I don't train a model online; I tune the policy's weights and thresholds from feedback. The naming is honest about this. It's adaptive policy tuning, not RL. It would become RL if you swapped the heuristic for a learned value function with bootstrapped targets, and that's a reasonable v2 direction. It isn't what's there today.
Act is where the autonomy boundary lives. v1 allows two autonomous actions, auto_sleep and auto_wake, both reversible. auto_sleep calls Chrome's tabs.discard() API, which frees memory but keeps the tab in the bar. auto_wake reactivates a slept tab when the user enters a related context (opening a Figma tab wakes the linked Notion spec from the same project group). What the agent never does is close a tab. Close is destructive: a closed tab leaves the browser, and getting it back requires the user. No autonomous policy of mine gets to take destructive actions, regardless of confidence. The cloud-layer LLM (used only for evaluation) cannot trigger browser actions at all. The local Gemini Nano controller has exclusive write authority over the tab state.
Learn runs after every autonomous action. The system records explicit feedback (Undo, Protect, Good, Bad) and infers implicit feedback from outcomes. A quick reopen after auto-sleep is a regret signal. A tab that stays slept for fifteen minutes without being requested is a confirmation signal. A manual wake right after auto-sleep is a stronger regret signal. These collapse into a simple reward map (safe_after_15m: +1, protect: -0.5, undo: -1) that nudges the policy's caution thresholds. I'm not trying to converge on a perfect policy. I'm trying to get less wrong over the course of a session about the specific user the controller is running for.
The benchmark, and what it shows
To compare Tab Agent against the dominant fixed-rule strategy, I built a scenario-grounded replay benchmark. Plausible browsing traces at three memory loads (10, 50, and 100 open tabs), each replayed under two policies: Tab Agent's adaptive controller, and a naive baseline that sleeps any tab idle for thirty minutes (the strategy used by The Marvellous Suspender and similar). Reload costs were calibrated to per-load delays (0.45s at 10 tabs, 0.95s at 50, 1.60s at 100) drawn from typical tab-discard reload measurements. The output is what I call modeled friction.
The hero figure is at the top of this post. Average friction per tab switch grows roughly linearly with memory load under both policies, but the slopes are very different. Tab Agent stays under 0.25 seconds per switch even at 100 open tabs. The naive baseline crosses 1.2 seconds. Across all three loads, the ratio is about 5.3x.
The more interesting plot is the second one.
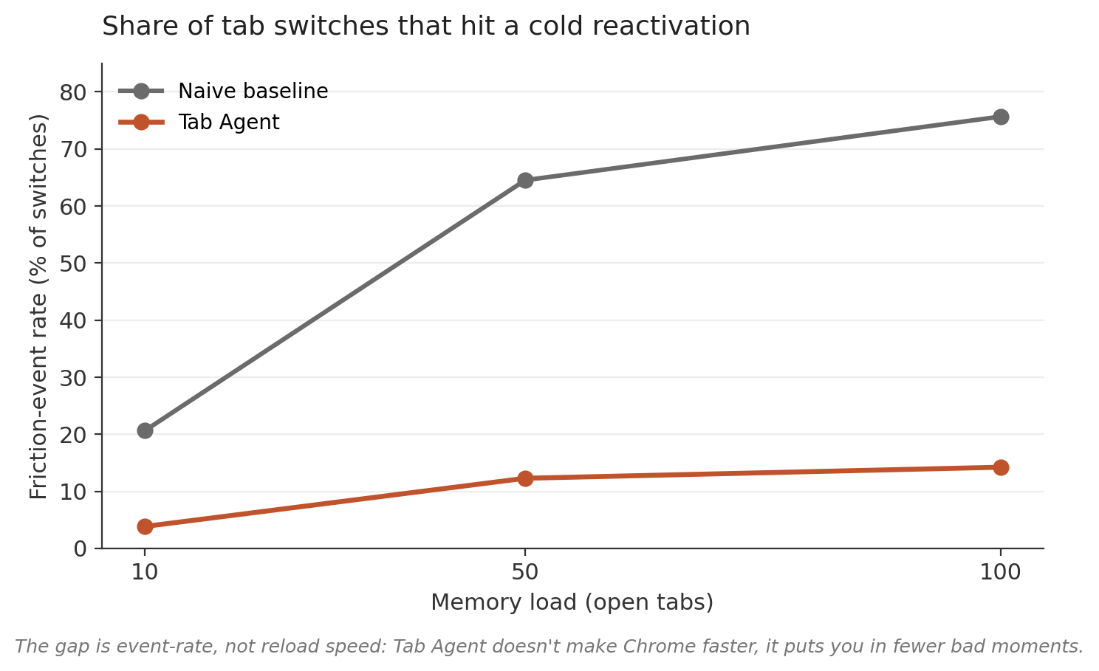
Same comparison, but the y-axis is the rate of friction events: the share of tab switches where the user hits a cold reactivation at all, regardless of how long it takes. At 100 tabs, the naive baseline lands a friction event on more than three-quarters of switches. Tab Agent stays around 14%. The gap between the two isn't that Tab Agent reloads tabs faster. It's that Tab Agent puts the user in a reload moment far less often.
That's the crux of why the prediction framing works. Per-event reload speed is a function of Chrome internals, page weight, and network. Tab Agent doesn't touch any of those. What it touches is the decision of whether you're going to be in that situation at all. A fixed-rule policy decides this badly because it ignores almost all relevant signal. A predictive policy decides it better because it doesn't.
What the benchmark isn't
The benchmark is policy evidence. It's not yet wall-clock evidence, and there's a real difference.
Reload delays in the replay are modeled, not measured. I calibrated them to plausible per-tab discard-and-reload costs at each memory load, but the current Chrome extension doesn't yet instrument real wall-clock timings on slept-tab reactivation. So when I report "0.23s average friction at 100 tabs," that number is the output of a deterministic model parameterized by published reload costs, not a stopwatch on a real machine. The shape and ratio of the comparison are robust to reasonable changes in those constants. The absolute numbers are not.
The replay traces are scenario-grounded, not user-recorded. They span realistic patterns (research sessions, multi-project knowledge work, shopping, single-domain research) but no real user generated the click stream. A v2 evaluation should replay traces collected from the live extension under both policies, which is what the cloud telemetry layer is designed for.
"Policy evidence" means the comparison shows the decision rule matters. Choosing tabs intelligently beats choosing tabs by clock time, by a large margin, on identical traces. It does not show that real users save real seconds in real sessions. That requires live instrumentation: timestamps on slept-tab reactivation, on navigation start, on the page becoming meaningfully usable again, on whether the wake was Tab Agent's call or a user-initiated request. The schema is designed. It hasn't shipped.
The right way to read the benchmark, then: the prediction framing produces dramatically less friction than the fixed-rule framing, in a controlled comparison where both policies are evaluated on identical traces and identical reload models. Real result, constrained scope.
What I got wrong, or haven't done yet
The controller is a heuristic, not a learned model. I use agent language because it's accurate at the architectural level (there's a real observe/predict/act/learn loop, and the policy does adapt), but the prediction step is a tuned scoring function, not a neural network. That's a deliberate tradeoff. Heuristics are debuggable, fast, and don't need training infrastructure or labeled data. The cost is that the policy's ceiling is lower than what a learned approach could reach. A v2 with a small on-device classifier trained on per-user labels is plausible and probably worth doing.
Memory savings shown in the extension's stats panel are estimated, not measured. I use a conservative ~50 MB per discarded tab based on industry averages for typical productive tabs. Real per-tab memory varies enormously: a Wikipedia article is 30-60 MB, Gmail is 150-300 MB, a video tab can hit 500 MB. The estimate is an underestimate for most productive sessions, which is the safer direction, but it isn't a measurement. Validating it against chrome.processes requires Chrome Dev channel, and that's a known gap.
The autonomy boundary is a product choice, not a technical limit. I could have given the agent close authority. I didn't, because the asymmetric cost structure makes it a bad bet at this confidence level. A wrongly-slept tab is 0.5 seconds. A wrongly-closed tab is potentially a lost form, a lost session, a lost morning. If the policy gets meaningfully better, this is a knob worth revisiting. Today it stays where it is.
Browser-only, Chrome-only, dependent on Gemini Nano being available on the user's machine. None of those are accidents (local-first, on-device, free-by-default were design constraints) but they are real boundaries on who the product works for today.
What this is actually about
Tab management is the surface. The thing underneath is that browser state should be personalized and predictive, not static and uniform. Chrome treats your tab bar like a flat list of equals because the browser was designed in an era when tabs were cheap and users had five of them. That era is over. Knowledge work in 2026 routinely runs at 30, 50, 100 tabs across multiple projects. At that scale a flat list with a single global rule is the wrong abstraction.
Tab Agent is one small instance of the right abstraction. The same shape generalizes anywhere "what should be in fast memory" is decided by a fixed rule: recently-closed-app behavior on phones, working-set decisions in the OS, tab-restore behavior across Chrome restarts. None of those are getting predictive treatment, for the same reason tab management isn't. Cleanup ships in an afternoon. Prediction means committing to a loop on the user's machine and being honest when it gets things wrong. Most teams pick the afternoon.
The afternoon is what your tab bar looks like.
Code: github.com/MaykaS/tab_agent. Web: tab-agent-web.vercel.app.
Benchmark is policy evidence under modeled reload costs. Wall-clock instrumentation is the next milestone.